
In the current rush to adopt agentic systems, the most dangerous question isn't "what can we make agentic?" but "where do agents actually help?" At Doximity, we’ve found that moving from a working demo to a production-grade agent requires a shift in focus—from model capability to system design.
That framing matters because a working demo and a production system are very different things. The demo proves something can work once. The product has to work repeatedly, with real users, real permissions, real data, and real failure modes. That matters even more in healthcare-oriented products like Ask, where information surfaced to clinicians helps support patient care. A few patterns are starting to feel useful:
Solve the Workflow, Not the AI
A valuable attribute of software engineering is knowing when not to overbuild. That sounds obvious, but it gets harder when the shiny new toy is genuinely useful. Agentic AI is one of those moments. Because agents can reason, call tools, and move through workflows in ways traditional automation cannot, it becomes tempting to look at every process and ask, “Could this be an agent?”
That is the wrong first question. The better question is: what does this workflow actually need? If the process is predictable, repeatable, and follows a known set of rules, it probably does not need an agent. It needs good automation, clean inputs, reliable APIs, and clear failure handling.
Agents become more useful when the workflow requires judgment: interpreting messy context, choosing between tools, adapting based on what it finds, or making decisions where the path is not fully known upfront.
That distinction matters because adding an agent is not free. It introduces new failure modes around reasoning, permissions, observability, evaluation, retries, and edge cases. Sometimes that tradeoff is worth it. Sometimes it is just a more complicated way to do what a well-designed workflow could have handled deterministically.
So the starting point should not be, "How do we make this agentic?" It should be, "Where does this workflow actually need reasoning, adaptation, and/or judgment?"
The Model is Just a Component
Model quality matters. Better reasoning, larger context windows, stronger instruction following, and better tools all help. But once an agent is operating inside a real workflow, the model is only one piece of a much larger system.
The output depends on the context it receives, the data it retrieves, the tools it can access, the permissions attached to those tools, and the way the workflow is orchestrated. Orchestration is where connectors, MCP servers, retrieval pipelines, and internal APIs become just as important as the model itself.
An agent might need to answer a question using data from Salesforce, Google Drive, Slack, Jira, a SQL database, and an internal knowledge base. The model can reason over that information, but the surrounding system still has to expose the right tools in a safe and structured way.
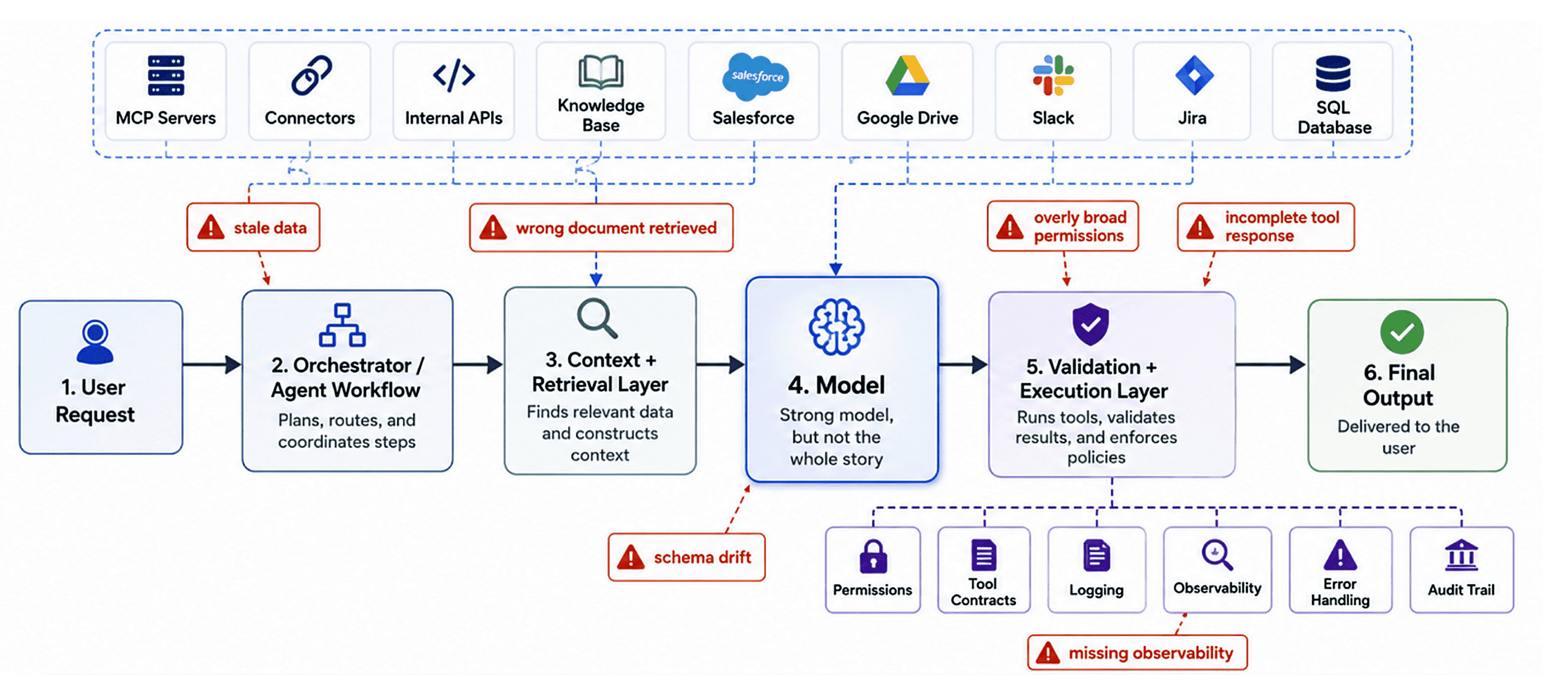
That means the system has to answer practical questions: Which tools should the agent have access to? What data is fresh enough to trust? Which actions are read-only versus write-capable? What should be logged when a tool is called? What happens if a connector fails or returns incomplete data?
An MCP server or connector layer can help standardize how agents interact with external systems, but it does not magically solve the product problem. If the connector exposes stale data, overly broad permissions, or poorly described tools, the agent can still produce a bad result.
From the outside, those failures often look like “the AI got it wrong.” Internally, the real issue might be data freshness, tool design, permissions, ranking logic, schema drift, or missing observability. The model may be the part everyone sees, but the quality of the output depends on the entire chain around it.
Bridging the gap between probabilistic AI outputs and deterministic engineering requirements is the core challenge. For production-grade systems, we prioritize observability, logging, and schema safety to ensure reliability.
Decompose Problems, Not Just Tasks
One pattern we’re paying close attention to is using a central orchestrator, or “puppeteer,” agent, an agent responsible for coordinating the workflow rather than doing every task itself.
In a code workflow, for example, the puppeteer might generate an implementation plan and then route that plan to several specialist agents before anything gets executed. One agent reviews the architecture, another checks company-specific code conventions, another looks at test coverage, another evaluates security or permission risks, and another checks whether the proposed change actually satisfies the original request.
Each specialist agent has a narrower prompt, a smaller tool surface, and a clearer definition of success. The architecture reviewer is not trying to validate every test case. The testing reviewer is not trying to make product tradeoffs. The security reviewer is not responsible for judging whether the UI feels right.
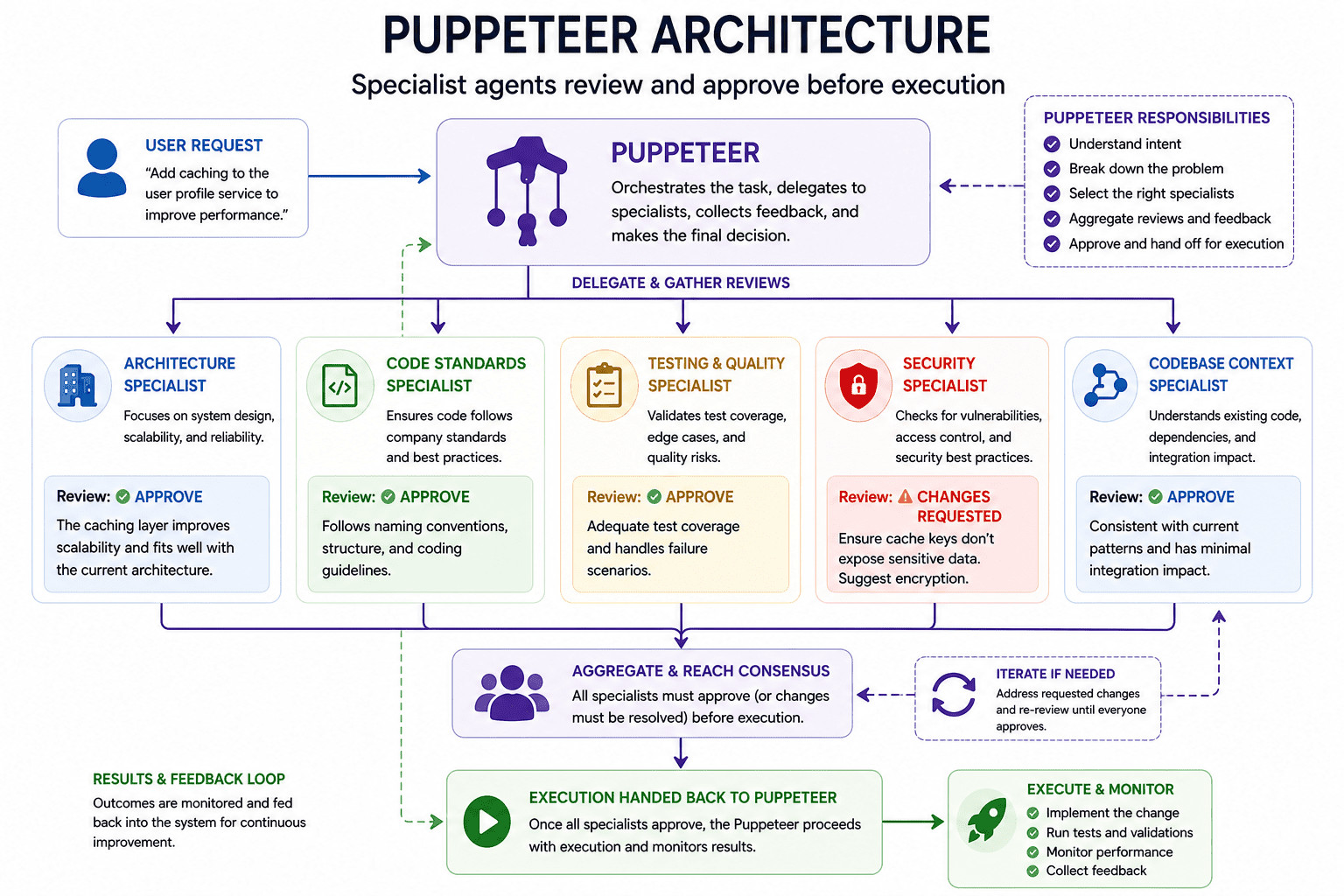
That separation matters because it makes the system easier to inspect. If a proposal fails, the orchestrator can tell where the concern came from: architecture, tests, security, codebase consistency, or requirements. It can then ask for revisions, rerun specific checks, or require a certain approval threshold before continuing.
This is not about creating a swarm of agents just because it sounds more advanced. For many workflows, that would be unnecessary overhead. The point is that once a task becomes complex or high-risk, one broad agent with a giant prompt and too many tools becomes difficult to trust.
A puppeteer-style architecture gives the workflow a control layer: one agent coordinates the process, specialist agents evaluate specific parts of the work, and execution only happens once the system has enough signal to move forward.
Encode Trust into the System
It’s not enough to say an agent “has access” to a system. Access needs to be broken down by what the agent is actually allowed to do. Reading a record, drafting an update, modifying a field, sending a message, or deploying code are all very different levels of risk.
That distinction matters even more in healthcare-oriented workflows. Physicians rely on Doximity products in high-trust environments, so an agentic system cannot just be capable; it has to be careful about what information it surfaces, where that information came from, and what level of confidence or review is required before acting on it.
This is the same distinction we think about in clinician-facing AI tools. Helping draft a referral letter or progress note is very different from sending it, saving it, or presenting it as final without review.
For example, an agent might be allowed to:
- Search approved medical or internal reference material automatically
- Help draft a referral letter for clinician review, but not send it
- Help draft a progress note, but require the physician to review and finalize it
- Suggest a profile or workflow update, but require approval before saving
- Run a dry-run version of a code change before opening a pull request
- Escalate when source confidence is low or the action is high-risk
That turns trust into something the system can enforce rather than something we hope the model understands. It also makes debugging possible. Every tool call should leave a trail: what the agent saw, what it tried to do, which tool it called, what data came back, whether it passed validation, and who approved the action if approval was required.
That is the difference between an agent that is merely capable and an agent that can be safely used in a real workflow. The goal is not to keep humans in every loop forever. The goal is to make autonomy conditional based on the risk of the action and the amount of control the system has around it.
In Closing
No finished playbook exists here, and that is the point. The tooling will change, the patterns will change, and much of what feels cutting edge today will soon feel obvious. But the core lens holds: start with the workflow, build the system around the model, keep responsibilities tight, and let earned trust determine autonomy. That is less dramatic than claiming agents will replace entire workflows overnight. It is also the only serious way to build with them.
Be sure to follow @doximity_tech if you'd like to be notified about new blog posts.