
At Doximity, we have nearly 20 data teams responsible for the development of data pipelines to support product and business intelligence needs. These teams rely on Apache Airflow to orchestrate over 900 active DAGs (fancy word for data pipelines), with dozens of updates deployed daily. However, with the growth of our data platform team, the bottlenecks in our deployment process for data pipelines could no longer be ignored. Deploying new pipelines or updating existing ones required building, publishing, and deploying a new Airflow container image—a process that could take up to 20 minutes. To make matters worse, pulling in the latest updates meant restarting Airflow services, causing temporary UI disruptions and delaying workflows—the salt in the wound, if you will.
In this article, we will discuss in further details the bottlenecks of our legacy deployment system and how we overcame them by developing a DAG synchronization service that continuously updates DAGs directly from Amazon S3 object storage. This new approach not only accelerated deployment times—reducing them from 30 minutes to under one—but also improved system reliability, reduced downtime, and enhanced operational flexibility.
Problem Overview
Prior to the sync service, DAGs were deployed by building them into the Airflow container image using a CI/CD pipeline. This was both time-consuming and resource-intensive, with each build and delivery process taking nearly 20 minutes to complete. With dozens of teams pushing updates daily, each triggering a full image rebuild, these delays were a clear bottleneck to our productivity.
Pulling in these changes required scheduled restarts of the Airflow Scheduler and Web Server at regular intervals. These restarts, while necessary, caused temporary (and dare I say, annoying) disruptions to the Airflow Web UI. Refreshing your screen only to be greeted by a 503 error was the virtual equivalent of stubbing your toe—frustrating and painfully avoidable.
Factoring in the Airflow image build time and the timing of scheduled restarts, deployment lag times could range from 20 to 40 minutes. In a world where Amazon can deliver a package within hours, waiting that long for a deployment feels borderline criminal. In the next section, we’ll discuss how we eliminated deployment lag times entirely (spoiler alert: no drones were involved).
Solution Design
It is important to provide some background context regarding our existing Airflow infrastructure, as it played a key role in designing an effective solution. Our production environment is hosted on AWS EC2 instances and orchestrated using Docker Compose. In the near future, we plan to migrate our Airflow stack to AWS Elastic Kubernetes Service (EKS). Given this, we needed a deployment approach that was simple, efficient, and decoupled from Airflow itself—one that would eliminate long rebuild times, and minimize downtime, while remaining flexible across different hosting environments.
As we explored potential solutions, we found that remote DAG syncing was a requested feature within the Airflow community. A proposal for a Remote DAG Fetcher was submitted as part of the Apache Airflow Improvement Proposal (AIP-5), but it was ultimately abandoned. While this confirmed there was a real need for a better DAG deployment strategy, there was no out-of-the-box solution to address it.
Turning to the official Airflow documentation, we found a set of best practices for managing DAG files.
- Building DAGs into the image (been there, done that).
- Syncing DAGs from project Git repositories using the Git-sync service.
- Mounting DAGs to a volume.
Options 1 and 2 were non-starters—we were already building DAGs into the image, and Git-sync’s limitations with multiple repositories made it a poor fit for our centralized Airflow service. That left us with option #3: mounting DAGs to a volume, leaving much to the imagination regarding how to actually sync DAGs into that volume. Our solution addresses this challenge in two parts: first, how DAGs are published from CI, and second, how they are synced with our Airflow stack.
Publishing DAGs
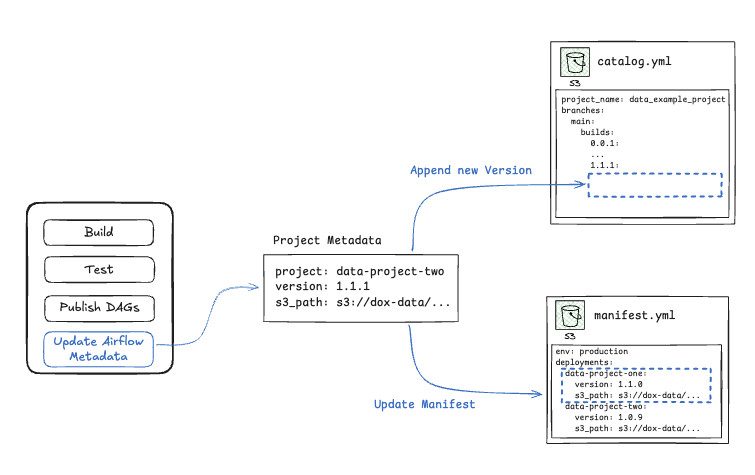
The first step in deployment is publishing DAGs to S3 and storing metadata for the sync service to track versions and retrieval paths. As part of the CI/CD pipeline, this metadata is broken up into two YAML files:
- A Project Catalog file that tracks the entire deployment history of a project. Think of it as a mail-order catalog (or an online store’s product inventory if you were born after the year 2000). Each time a project publishes DAG updates, we append metadata to the catalog file detailing the project name, version, S3 archive path, and creation date for each deployment.
- The Airflow Manifest File – This defines which project DAGs are actively synced to Airflow. Similar to how a ship manifest lists all crew members aboard, the airflow manifest file keeps a record of the actively deployed data projects and their corresponding version.
As pictured in the figure above, these two files are updated every time project DAGs are published. A new version is appended to the catalog, and the manifest is updated in place. Once the manifest file has been updated, the airflow DAGs are ready to be synced to the mounted volume.
Syncing DAGs
The DAG sync service is a lightweight, containerized application that periodically checks the Airflow manifest file stored in S3 at a configurable cadence, which in our setup runs once per minute. Each project listed in the manifest may contain multiple DAGs, all of which must remain in sync. During each sync cycle, the service downloads the Airflow manifest from S3 and compares the listed project DAGs against those currently in the mounted volume. Based on any detected differences, it applies the following updates:
- New projects (added to the manifest) are created by downloading all associated DAGs from S3
- Updated projects are refreshed by replacing outdated DAGs in the volume with the updated version published to S3
- Archived projects (removed from the manifest) are deleted from the volume
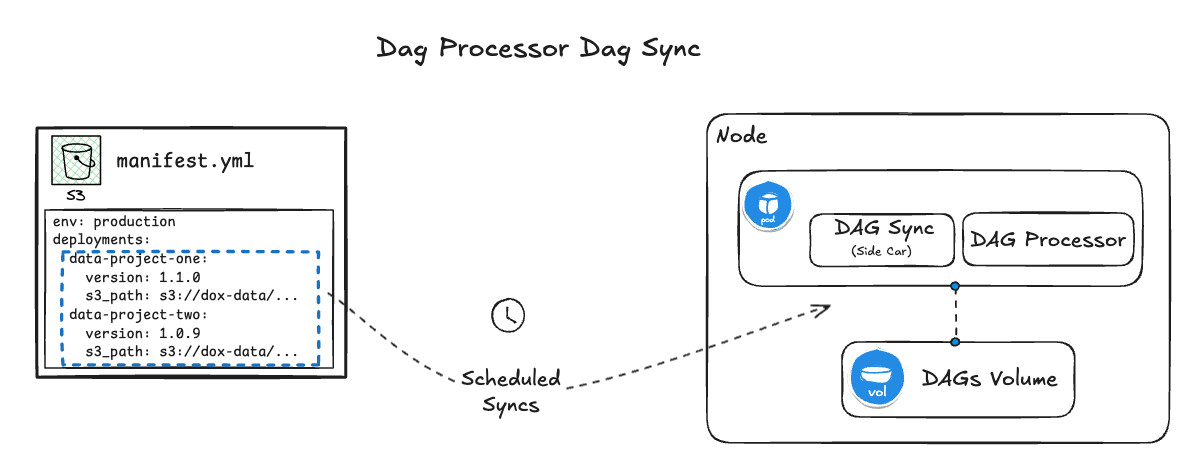
We use this service to update the mounted DAGs for Airflow’s DAG processor and worker components, ensuring they always have the latest versions available. For the DAG processor, the sync service runs as a sidecar container, downloading and updating DAGs every minute to match the manifest file.
Deploying the DAG sync service for workers varies depending on the Airflow executor, which controls how task instances are run by workers. The two most common choices for large-scale workloads are the Celery and Kubernetes executors. Celery workers run continuously, pulling tasks from a queue, while Kubernetes workers are ephemeral, spinning up for a task and terminating once it's complete. For more information on the trade-offs of these architectures, the official Airflow documentation provides a detailed overview.
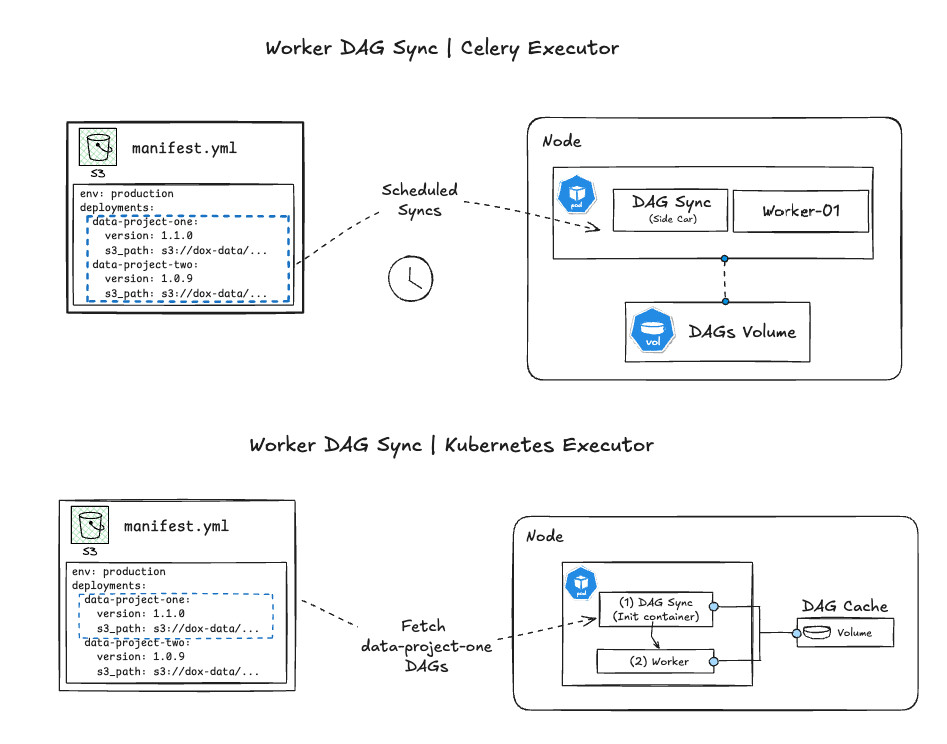
With Celery workers, the DAG sync service follows the same approach as the scheduler, running as a sidecar container that continuously updates the DAG volume to reflect the latest state in the Airflow manifest.
Kubernetes executors require a different strategy since workers are ephemeral, spinning up for a task and terminating afterward. A sidecar container isn't reliable in this setup, as there’s no guarantee DAGs will be available before execution. Instead, an init container—a temporary container that runs before the main application starts—pulls and mounts the necessary DAGs before the task runs. To minimize startup latency, only the relevant DAGs for the specific project are retrieved rather than the entire manifest.
Conclusion
By syncing DAGs directly from S3 to a mounted volume, we’ve eliminated the need to rebuild Airflow images or restart services to apply DAG changes. Deployment lag times have dropped from 20–30 minutes to just one, cutting down long coffee breaks and time spent on Hacker News (probably the solution’s biggest limitation, if I’m being honest). Beyond speed, this approach prioritizes simplicity. Instead of relying on a database, we store deployment metadata as YAML files in S3, minimizing infrastructure overhead. This lightweight design makes it easy to roll out changes across pre-production, staging, and development environments without added complexity. Lastly, a containerized DAG sync service also makes deployments more transparent. With monitoring and logging in place, it’s easy to track changes, troubleshoot issues, and ensure DAGs are always up to date.
What started as a complex challenge led to a simple, effective solution—one that remains flexible, decoupled from the intricacies of Airflow, and easy to maintain as our infrastructure evolves.
Be sure to follow @doximity_tech if you'd like to be notified about new blog posts.