
Automating workflows is key in setting your team up for success. We believe in building tools to help others focus on their craft rather than the nuances of process. These are the tools we rely on to improve our engineering workflow at Doximity:
Setup
Jumping into new applications can be daunting. Learning the code and its business rules isn't enough. There are many dependencies to install and configure. Early on, we relied on README files to setup development environments. This worked well, but it was a manual process and consumed too much time. We are a Rails shop. Therefore, we rely on bin/setup to configure our environments.
git clone git@github.com:doximity/application.git
cd application
./bin/setup
The above three commands are all one should need to bootstrap our applications. Our bin/setup includes installing brew and other system libraries. Here is a trimmed example of a few items from our bin/setup:
puts "== Installing brew & friends"
system 'ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"'
system 'brew update'
# Ruby
system 'brew install rbenv'
system 'brew install ruby-build'
system 'rbenv install -s $(cat .ruby-version)'
system 'gem install bundler'
system 'gem install bundler --conservative'
system 'bundle check || bundle install'
# Rails
puts "
== Preparing database"
system 'bin/rake db:setup'
puts "
== Removing old logs and tempfiles"
system 'rm -f log/*'
system 'rm -rf tmp/cache'
puts "
== Restarting application server"
system 'touch tmp/restart.txt'
Integration

Once a team member is set up with an application, the next concern is merging commits into master. In our setup, they can rely on alerts to stay informed of errors. We encourage every new team member to deploy their code to production on day one. It’s vital they feel comfortable around our safeguards. Let's delve into some of them.
Continous Integration
Whether we are running rSpec or minitest, we ensure every commit has an automated test suite ran against it. On completion, it's reported to the GitHub Pull Request and the respective Slack channels. Setting up Continuous Integration should be trivial with all the tools on the market. CircleCI is our choice except for our mobile builds, for which we use Jenkins.
Pro Tip: parallel_tests can speed up builds while getting the most out of the VMs to save money.
Instant Gratification
Having good test coverage is important, but if it takes hours to finish the build, it slows down your team. A fast build is a requirement. In our early days, our largest application’s test suite took 4 hours to run. Over the years, we’ve brought it down to 20 minutes by having a dedicated TestOps team who improved our test infrastructure. Smaller applications don't consume as much time, finishing in under 3 minutes. Consider how much time your team waits for a build to finish. That’s time users are deprived from the next new feature or a critical bug fix.
Code Metrics
CodeClimate can be an invaluable tool. It keeps your code lean and secure. Ensure your repository is hooked up to notify on Pull Requests so your team knows of issues before merging into master. Brakeman is also a good resource for analyzing security vulnerabilities.
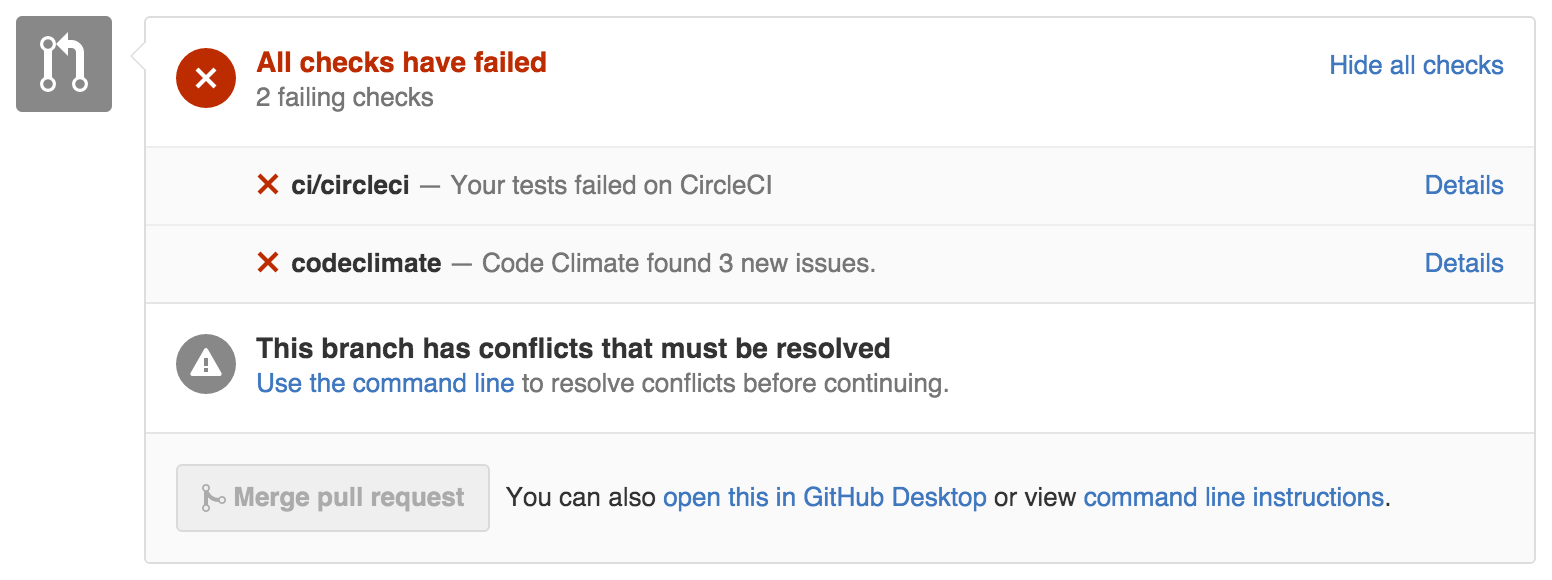
Most aren't brave enough to deploy to production when their pull request looks like above.
Delivery

Delivering your branch to production should be trivial -- but we all know it's not always that simple. Even with green automated tests, there is still a chance your branch can cause havoc in production. Perhaps it's the missing index which goes unnoticed in development. In the context of millions of rows in production, the impact can be drastic. Here is how we combat this.
Staging and Production
Staging environments are common for testing before production deployment. Parity between these environments is critical. Ideally these environments replicate production as closely as possible from the NGINX configuration to production data stores. We use the following tools to build hundreds of environments in various clusters.
Packer
We ensure there are base images created via Packer templates with Ruby installations, speeding up the time it takes to bootstrap new environments.
Terraform
The biggest wrench in our toolbox is Terraform. We configure a lot with Terraform. Environment creation, IAM policies, S3 buckets, Route 53 records, Consul key/value stores, and many others. The following is a simplified version of our Terraform configuration with documentation:
# Providers and its configuration. In this case AWS, Consul and Digital Ocean.
provider "aws" {}
provider "consul" {
scheme = "http"
datacenter = "[redacted]"
address = "[redacted]"
}
provider "digitalocean" {}
# Digital Ocean droplet that provisions the new instance with Chef Server and runs chef-client.
resource "digitalocean_droplet" "web" {
name = "${var.app}.${var.cluster}.${var.domain}"
image = "${lookup(var.image, var.ruby_version)}"
region = "${var.region}"
size = "${var.size}"
private_networking = true
provisioner "local-exec" {
command = "knife bootstrap ${self.ipv4_address} -N ${var.app}.${var.cluster} -y -x root --bootstrap-vault-item secrets:base -j '{"rbenv": {"version": "${var.ruby_version}", "global": "${var.ruby_version}"}}' -r 'recipe[app-ruby::${var.stage}]'"
}
}
# Route 53 record for the new application pointing to the Digital Ocean droplet.
resource "aws_route53_record" "dns" {
zone_id = "${var.aws_route53_zone_id}"
name = "${var.app}.${var.cluster}.${var.domain}"
type = "A"
ttl = "300"
records = ["${digitalocean_droplet.web.ipv4_address}"]
}
# IAM user and access key.
resource "aws_iam_user" "user" {
name = "${var.cluster}-${var.app}"
}
resource "aws_iam_access_key" "key" {
user = "${aws_iam_user.user.name}"
}
# S3 bucket.
resource "aws_s3_bucket" "b" {
bucket = "${var.cluster}-${var.app}-${var.stage}"
acl = "private"
}
# Access policy for this user to the S3 bucket.
resource "aws_iam_user_policy" "b_ro" {
name = "${var.cluster}-${var.app}-${var.stage}-s3-access"
user = "${aws_iam_user.user.name}"
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": ["s3:*"],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::${var.cluster}-${var.app}-${var.stage}/*",
"arn:aws:s3:::${var.cluster}-${var.app}-${var.stage}"
]
}
]
}
EOF
}
# AWS keys and S3 bucket names into Consul so it can be accessed by the Rails application.
resource "consul_keys" "app" {
key {
name = "aws_access_key_id"
path = "${var.stage}/${var.cluster}/${var.app}/AWS_ACCESS_KEY_ID"
value = "${aws_iam_access_key.key.id}"
}
key {
name = "aws_secret_access_key"
path = "${var.stage}/${var.cluster}/${var.app}/AWS_SECRET_ACCESS_KEY"
value = "${aws_iam_access_key.key.secret}"
}
key {
name = "s3_bucket_name"
path = "${var.stage}/${var.cluster}/${var.app}/S3_BUCKET_NAME"
value = "${aws_s3_bucket.b.id}"
}
}
Adding new environment involves the simple configuration shown below and running terraform apply:
module "APPLICATION_CLUSTER_DOMAIN_TLD" {
app = "APPLICATION"
cluster = "CLUSTER"
size = "2gb"
ruby_version = "2.2.2"
source = "./app"
}
Chef and Capistrano
Once Terraform finishes, Chef takes over provisioning everything that’s required by the Rails application. At that point, Capistrano handles all our deployments.
Deployments
Ensuring your team (whether it’s engineers or not) can deploy via ChatOps can be a huge time saver. Besides, it allows us to queue up dozens of deployments.
At Doximity, we rely on a combination of Slack, Hubot, and Heaven to handle deployments. For better visibility, we've customized Heaven with a user interface. It reports status checks on the individual environments along with deployment history.
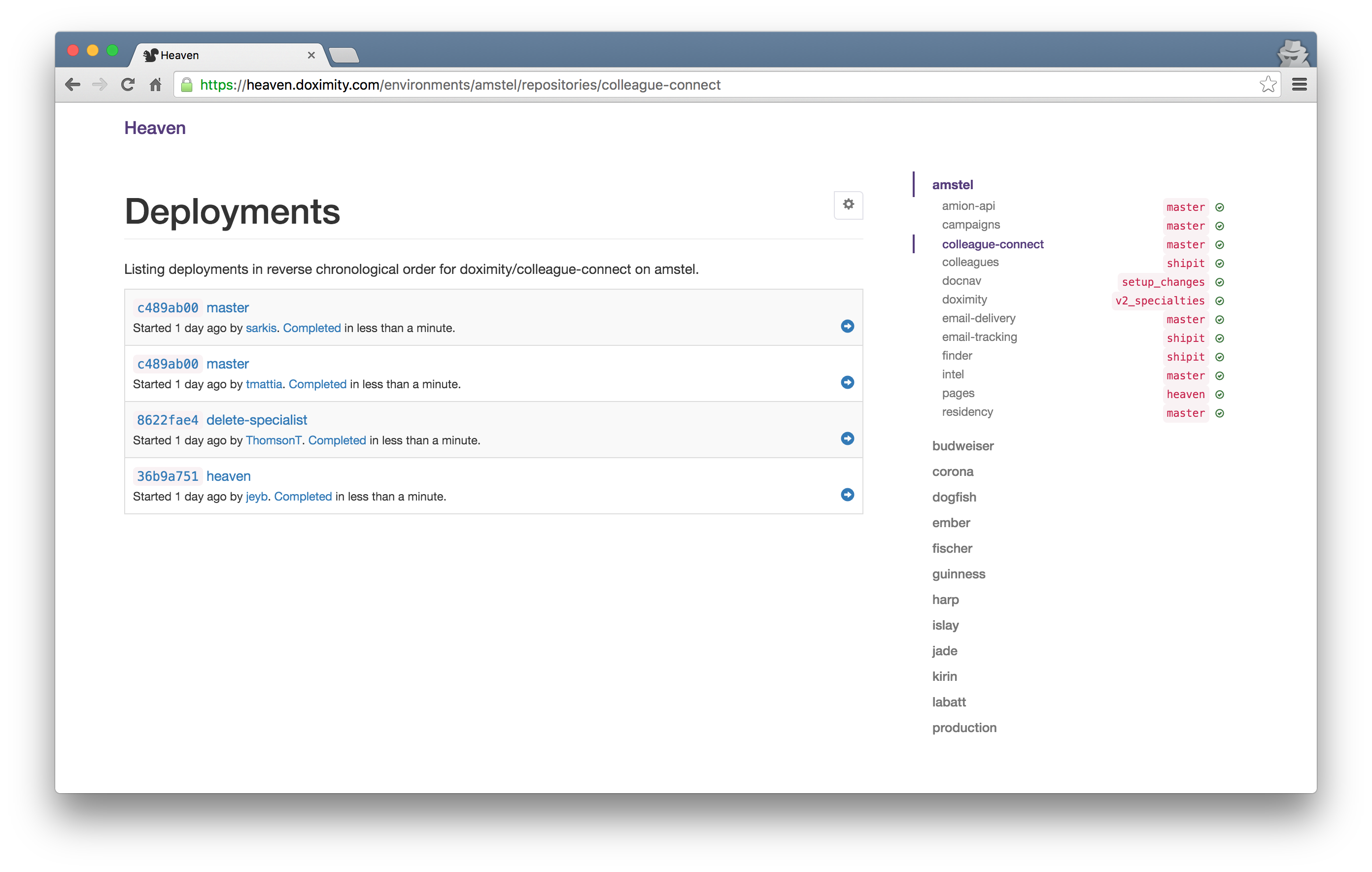
Pro Tip: Lock deployments to production at Beer O’Clock.
Migrations
Migrating tables are common and they should be trivial to perform via ChatOps. With the combination of Capistrano, Hubot, and Heaven, this should be doable by everyone. Migrations have dangers such as locked tables and missing columns. This results in either downtime or errors for users. Relying on Large Hadron Migrator, we perform live migrations without downtime for our users.
Monitoring

Everyone on your team should be able to react to performance problems and address them with ease. After all, It’s Not Done Until It’s Fast. We use a combination of NewRelic for application reporting and Sensu for server monitoring. VictorOps alerts us when we aren’t by our computers. Otherwise, notifications are delivered to the Slack channel.
Combining the aforementioned tools, we help our team ship product faster and be more confident with what they deliver.
Developer happiness is an important but often neglected subject. Once a team surpasses a few engineers, optimizing for developer productivity is imperative. Our team caught this train a little late, but we're making strides now. Expect to see a few more articles about this topic here. Follow us for updates.