
At Doximity, we go to great lengths to ensure the quality of our products aligns with the standards physicians require. Across various industries, Large Language Models (LLMs) have become the backbone of numerous applications, driving advancements in everything from natural language processing to automated content creation. As we continue to develop products that make use of these LLMs, the need for rigorous and comprehensive evaluation of their outputs has never been more critical. Strap in as we explore the process for evaluating our Doximity GPT product, Doximity’s HIPAA-compliant medical writing assistant, focusing on the importance of using "ground truths" to establish baseline metrics and the relative performance of contender models.

A Brief Overview of How LLMs Generate Outputs
LLMs are trained on vast amounts of textual data in order to learn patterns, structures, and nuances of language. By processing this data, these models develop the ability to generate text that mimics human writing. The output generation process involves the model understanding the input prompt, enhancing its focus via a system prompt, running all of that through its learned information and constructing a coherent and contextually relevant response. While this capability makes LLMs incredibly versatile, it also introduces unique challenges in ensuring the outputs meet specific quality and accuracy standards.
LLM Evaluation: What is it and Why Does it Matter?
Accuracy, precision, and recall are standard metrics that help evaluate different aspects of classification model quality in machine learning, and these metrics are still incredibly important for LLM evaluation as well. Additional traditional methods include manual review and comparison against predefined benchmarks. However, as LLMs grow more complex, these methods become less feasible due to the sheer volume of outputs and the nuanced understanding required to assess them. In addition to standard machine learning performance metrics, LLM assisted evaluation techniques have become especially helpful in filling the gaps in understanding of LLM model responses, both in the presence and absence of labeled data. These techniques involve assessing the content on its relevance, coherence, factual accuracy and adherence to ethical guidelines. This has led to the development of more sophisticated evaluation frameworks, including the use of golden datasets1.
DoximityGPT is designed to streamline time-consuming administrative tasks for our Clinicians, such as prior authorizations, patient documentation, medical letters and more. In order to do that, the model needs to produce factually accurate information in the precise structure that Clinicians need it. Through quantifying these and other attributes with evaluation metrics, we are able to determine the best model available for the task (Model Evaluation) as well as tune various levers of the model system (System Evaluation) that are within our control, such as prompt templates, system prompts and context, to not only ensure our current application is providing reliable and accurate responses, but also ensure that we have visibility into ongoing opportunities for improvement.
Preparing Our Ground Truths
While the landscape for evaluating LLM outputs is vast and evolving, there is one commonality that is shared across them all: the immense value of a dataset that holds your ground truths. This is sometimes called a "golden dataset." A golden dataset begins with the careful selection of prompts that are representative of the LLM's intended use cases. We built Doximity GPT as a general purpose assistant for healthcare professionals, and over time, our users have crowdsourced an extensive library of prompts that save them countless hours of work. A golden dataset for Doximity GPT means choosing prompts that reflect the diverse and complex nature of medical inquiries and working with Doximity Medical Fellows as humans-in-the-loop2 to categorize prompts based on their domain, ensure a broad coverage of topics, prompt tuning to elicit clear, concise, and informative responses from the LLM, and curation of ideal responses for every single one of these library prompts. This curated prompt library serves as the foundation for generating high-quality output examples for evaluation.
Running Evaluations
Creating Sample Data
In order to get representative evaluation results, we need to consider replicating each prompt a number of times so that we can capture the variance in responses between input runs. For our use case, we replicated each prompt 10 times, taking our evaluation set from 157 prompts to 1570 prompts to be run and evaluated.
Selecting Evaluators
For our initial evaluation, we determined that the best suited evaluators for our goals were:
Correctness: The evaluator determines correctness by looking at the reference answer. It compares the answer (ground truth) with the result (generated output). When they match, it outputs "correct".
Contextual Accuracy: The evaluator determines if a result (generated output) is correct or not based on the context of the results (without ground truths).
Conciseness: The evaluator uses chain-of-thought reasoning to assess "Is the submission concise and to the point?"
Helpfulness: The evaluator uses chain-of-thought reasoning to assess "Is the submission helpful, insightful, and appropriate?"
Embedding Distance: The evaluator measures the distance between a ground truth and an LLM output by quantifying the semantic similarity/dissimilarity between them. We leveraged cosine similarity for this calculation.
Determine Evaluation Model
The model used for generating evaluations does not have to be the same model that is being evaluated. In fact, sometimes it can be more cost effective to use an open-source or less expensive model for running evaluations. For our use case, we started with GPT-3.5-Turbo to evaluate our model which is utilizing GPT-4. Upon deeper investigation of the evaluations, we quickly spotted several instances of hallucinations in the evaluation metrics reliant on chain-of-thought reasoning. Therefore, we decided that it was important at this time to leverage the best model available to generate our baselines.
Implementation
Langchain is a versatile open-source framework that enables developers to build applications utilizing LLMs3. You can think of it as a Swiss Army knife for AI developers, with implementations available in both Ruby and Python. Most of the evaluators we chose are available "out-of-box" from Langchain; and, the framework also included the ability for us to craft custom evaluators, which makes this toolkit especially versatile for our evolving business needs. Langsmith was built on top of Langchain to create an observability layer for the inner workings of these LLM-based applications. Additionally, everything that is run with Langchain can be easily traced to Langsmith for monitoring and investigation purposes.
Since we were already leveraging Langchain for LLM development, it was a natural extension of our existing framework to introduce their evaluations into our pipeline. By tracing our runs and evaluations to Langsmith, we could dive deep into the various evaluators and also access all of our runs and evaluations as datasets to analyze more in depth for benchmarking purposes.
Analyzing Evaluation Results
By calculating sample means for each metric, we were able to evaluate 95% confidence intervals for the metrics produced by GPT-3.5-Turbo and GPT-4. Almost every single metric had a statistically significant difference between the two models, with GPT-4 performing best. The only exception was Conciseness, which resulted in a statistically insignificant difference between the sample means. These metrics serve two purposes: a baseline for all future models to be considered, and quantifiable evidence that GPT-4 is providing us with higher quality responses.
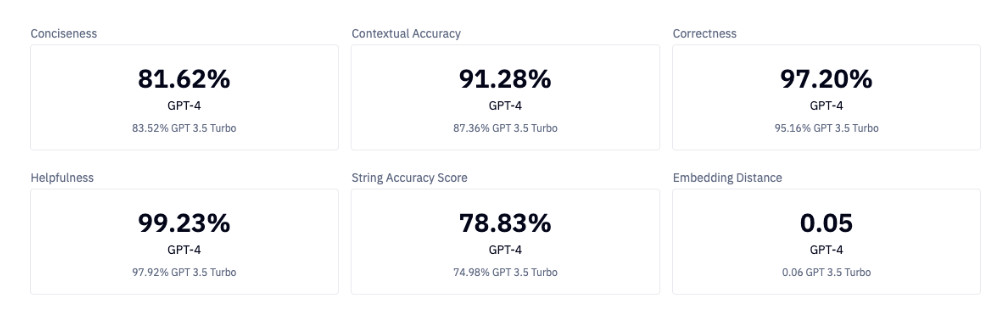
Furthermore, by calculating sample means at the prompt template level, we will be able to identify where our current system may be struggling in terms of the system prompts and templates being used. These prompt level baselines are a starting point to provide meaningful feedback on system and user prompt tuning in the future.
What’s Next?
With a set of benchmarks and a framework for ongoing evaluation metrics in hand, we are in a position to rapidly iterate and experiment with system and model changes with consistency and reliability. Next up is hooking this up directly into our application workflow so that we will have observability into ongoing performance, an interactive system to gather human-in-the-loop feedback and a baked-in set of online and offline evaluation metrics to determine the success or failure of variations in the system changes.

The evaluation of LLM outputs is a complex but essential process in order to ensure that LLM-based applications, like Doximity GPT, deliver accurate, reliable, and ethically sound content. By adopting a structured approach, as demonstrated through the creation and use of a golden dataset, we have been able to navigate the challenges of LLM evaluation with greater precision and confidence. As LLMs continue to evolve, so too will the methodologies for their evaluation, promising ever-greater levels of sophistication and accuracy in the AI-driven content of the future.
Acknowledgments: I am grateful to Valentino Stoll and Dr. Bushra Anjum for their feedback and proofreading support for this article.
Be sure to follow @doximity_tech if you'd like to be notified about new blog posts.