
If this article piques your interest and you would like an opportunity to do your best data work in a unique and truly data-driven environment, you're in luck: ⚡ we're hiring! ⚡
Building a company where data is fundamental has resulted in many unique challenges—one of which is how to organize our data teams. But before diving into Doximity’s data team structure, let's set the stage.
Doximity is commonly mentioned as the “LinkedIn for doctors” and although partially accurate it only captures a portion of our story. Today, Doximity assists medical professionals with career navigation, secure peer-to-peer communication, telehealth (Dialer), medical news and research discovery, Locum Tenens opportunities (Curative), and, most recently, clinical scheduling (Amion). I like to say that we are more of a Swiss army knife for medical professionals.
Already unique in terms of our offerings and network, which includes over 2 million U.S. healthcare professionals, including over 80% of U.S. physicians, we are also unique in that we are a profoundly data-driven company. Not only do we leverage data for business intelligence and decision support, but data directly drives the majority of our products.
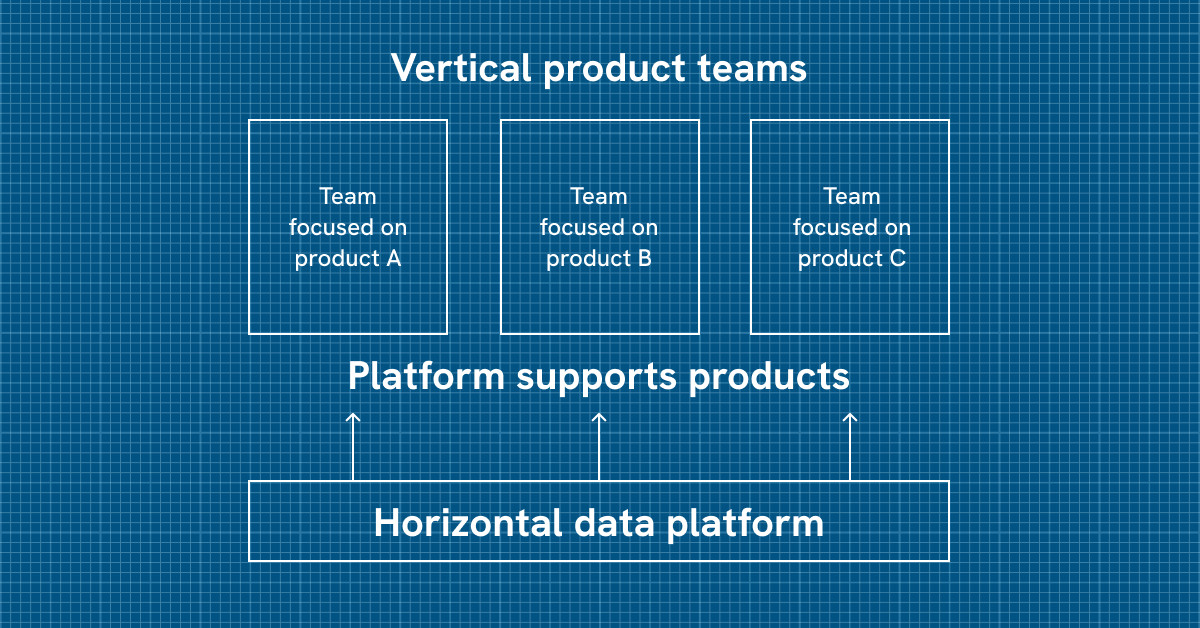
Through talking with industry peers, it is my experience that even in today's increasingly data-driven world, many organizations still leverage an older strategy for organizing their data teams. In short, most companies have a data analyst team and a data engineering team. The division is purely functional, and if there's a need for data infrastructure, you will often find it managed by members of the general operations team. Being big proponents of domain-driven design we do not believe it is possible to achieve the best performance for modern high-performance data organizations using this model. Instead, at Doximity, we have multiple cross-functional product teams where each team is responsible for a specific product (or part of a product). These product teams are generally composed of data analysts, data engineers, and product managers, all coming together to focus on driving forward a specific part of our data endeavors.
At this point, you might wish to interject and mention that this model might seem like an ideal setup for forming silos, and I would be the first to agree. There's a dilemma. On one end, we want our product teams to move as fast as they can in the direction they need to go to push their area of ownership forward. But we also wish to set up the teams for collaboration, cross-team discussions, easy movement of people between teams, ability to help each other and contribute to making the whole of data at Doximity better.
In other words, we need a shared language across our data teams. Our solution is the Doximity Data Platform. Contrary to the vertically-focused product teams, the Data Platform operates horizontally, creating a foundation on which all other teams work. It's a delicate balance of creating standards, shared infrastructure, tools, services, systems, and core datasets while simultaneously avoiding restraining and guardrailing our product teams to the extent that we hamper innovation and exploration. We attempt to provide this balanced Data Platform to our product teams through four foundational teams: Data Infrastructure, Data Services, Data Integration, and Product Analytics.
The Data Infrastructure team is probably most easily comparable to a traditional operations team. We are responsible for managing our AWS accounts (primarily through Terraform), our Snowflake deployment, our containerization (our data stack is Dockerized, and we're exploring a move towards K8s), and our CircleCI CI/CD automation. The main goal is to reduce the incidental complexities which arise when working with a modern data stack. Although undoubtedly a buzzword, we strive to democratize access to data at Doximity. It is not unusual for a data analyst to build and own a data pipeline. A large part of what makes this possible is the kind of automation that the data infrastructure team implements that ensures data endeavors at Doximity are simple.
The Data Services team, a sibling team to Data Infrastructure, shares the goal to reduce incidental complexities faced by data teams. But Data Services tackles the problem and carefully guides our data stack toward a simpler environment by focusing on the service layer. The Data Services team builds and evolves our shared python libraries to simplify everyday or complex data tasks. We standardize access to data stores, create shared A/B testing tools, build common testing fixtures and plugins, and maintain our in-house version of DBT (we like DBT, we just happened to build our solution before DBT gained wider popularity and maturity). We prioritize our work to increase the number of data members that can tackle data challenges while also increasing the time data team members can spend on the actual complexity of the data projects they undertake.
As you might guess by its name, the Data Integration team is responsible for merging external data into the datasets residing within Doximity’s foundational data layer. The unique property of a foundational dataset is that it powers multiple products of the platform. This generates a unique opportunity for us, as any changes we make have wide reaching consequences. Integrating new data, de-duplicating inconsistent entries, or finding novel ways to connect data points will cascade across the dependent products. I often describe Data Integration as a team that can change one dataset, and suddenly, multiple seemingly independent products perform better. Not because we changed the product behavior directly, but because we improved the data that underpins the products.
Last but not least is our Product Analytics team. While each product data team is responsible for the analytics to understand their area of responsibility, the Product Analytics team combines metrics, insights, and data from all products and aggregates them to help us holistically understand the company's performance. We primarily focus on understanding Doximity's insight needs and curate, transform, and define data to meet those needs. Specifically, the Product Analytics team produces carefully defined dimensional models (Kimball), associated dashboards (Looker), and thorough analyses (Hex) for consumption by key decision-makers. Besides the actual movement of data and expertise in modeling, a big responsibility of this team is to ensure clear and precise data definitions. For example, without the efforts of the Product Analytics team, it's easy for even fundamental definitions such as "active user" to be defined slightly differently across teams, resulting in problematic inconsistencies when key decision-makers are comparing the numbers driving their decisions. The Product Analytics team ensures clear shareable data definitions across Doximity through their data modeling.
In conclusion, Doximity is far from your average data organization. We thrive in data and, as a result, are organizing ourselves to meet the unique demands of a truly data-driven organization. Data is everywhere, from products to business intelligence, and our cross-functional product teams are pushing the envelope in the direction they need to build the future of Doximity. Still, collaboration across teams continues; data people can compare notes, collaborate, discuss data challenges and fairly seamlessly move between teams. The shared language that the Data Platform teams provide enables this unique organizational reality. But nothing is perfect, and our Data Platform journey is far from complete. We aim to continue to reduce incidental complexities, while improving our shared language across teams, and providing solid foundation for our data endeavors.
Thanks to all the reviewers.
Be sure to follow @doximity_tech if you'd like to be notified about new blog posts.