
Data modeling required for the online transactional processing (OLTP) systems’ databases is inherently different than the data modeling needed for analytics supported by a data warehouse. The data modeling for the analytics is called “Dimensional Modeling.” So what is this technique, and why do we need it? Let’s explore.
The concept of dimensional modeling was developed by Ralph Kimball and is relevant to any data practitioner in today’s data ecosystem. Dimensional data modeling is a database design technique used to restructure existing data for easy and optimized querying. The data model primarily consists of two types of tables, fact tables and dimension tables. A fact table contains facts, which are measurements from a business process event and correspond to an observable physical event such as a sale, purchase, processing, snapshotting, engagement, etc. Facts could be additive, semi-additive, or non-additive. A dimension table provides the context surrounding the business process event that generated those facts. Thus dimension tables have descriptive attributes and define “the 5 W’s and the H” (Who, What, When, Where, Why, and How) of the event.
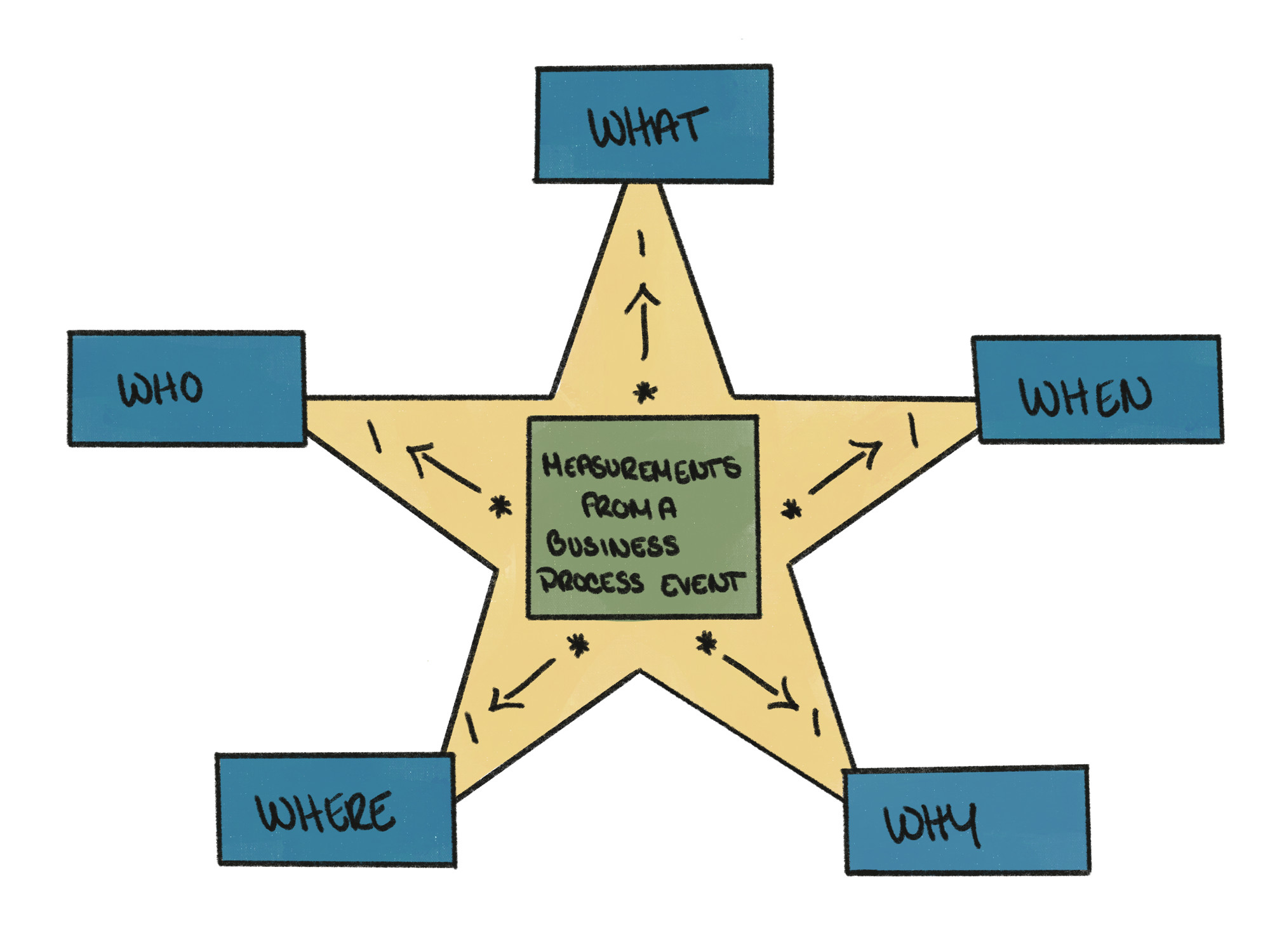
Dimensional modeling results in more intuitive data structures for writing queries with good performance. The modeling principles, such as discussed here, make exponentially complicated data simple to use for a wide range of business problems and technical expertise. Each model, or star schema, is self-contained and self-explanatory. Hence interested users of any technical background can comprehend and run analytical queries against them without having to understand a mesh of normalized tables.
Relational data models, such as used by MySQL, Microsoft SQL Server, Oracle DB, IBM DB2, are optimized for real-time CRUD (create, read, update, delete) operations while ensuring ACID (atomic, consistent, isolated, durable) guarantees. Whereas, dimensional models are focused on user understanding and reduced data latencies while manipulating large volumes of data. For an easy reference, below are some of the differences between the transactional relational model and the dimensional model.
| Transactional Relational Model | Dimensional Model |
|---|---|
| Normalized (3NF) | Denormalized |
| Little to no redundant data | Redundant hierarchical data |
| Reflects the most current state | Requires historical context to be preserved |
| Optimized for CRUD operations on a small number of rows (KBs to MBs) | Optimized for retrieving and aggregating results spanning many, if not all, rows (GBs to PBs) |
| Works well with row stores | Works well with column stores |
| Data consumers are OLTP (online transaction processing systems) and software engineers | Data consumers are analysts, data scientists, software engineers, commercial, and business people |
| Protects transactional integrity (ACID guarantee) | Is the “simple and fast” source of actionable information |
Another advantage of the dimensional model is its extensibility. By design, dimensions are modular, and can and should be reused. This allows building a data warehouse in an agile, incremental fashion. As multiple business processes share dimensions, this enables overall conformity. Also, having one version of the truth, i.e., coherent dimensions, allow business users to analyze data better. Dimensional model integrates various business processes in an application-agnostic manner.
At Doximity, we use dimensional modeling extensively for our analysis and reporting. We have daily ETL (extract, transform, load) jobs running via Airflow that load production data from MySQL into fact and dimension tables in Snowflake. Further, we have hourly and daily tasks that utilize this modeled data and create interactive multi-level dashboards using Looker.
As an example, one such set of dashboards are built on the dimensional model of user engagement. A simplified version of the star schema is reproduced below. The fact table enables numerous aggregations on user engagement, by user attributes, medical specialties, Doximity products (newsfeed, digest, jobs, etc), platform (iOS, Android, web), and over multiple time frames. We also calculate advanced metrics such as daily active users, weekly active users, monthly active users, and quarterly active users using this data.

Notice how in this dimensional design, specialties and users are two unlinked tables that can be independently joined to user_engagement through corresponding foreign keys in the fact table. In a normalized, transactional design, specialties would be permanently linked to users through a foreign key from the specialties table. Then, the user_engagement table would link to the users table. Hence in a transactional design, any analysis consisting of only specialties based engagement will have to have an intermediate join with users. In a dimensional design, however, all contextual entities required for aggregation and analysis are directly linked to the fact table as independent dimensions. This creates some duplication (such as the field specialty code in users) but allows for both simplified design and performant joins, which are key benefits of dimensional design philosophy. Hence, in this case, specialties is an independent dimension that can be used to aggregate and query the engagement data without joining through users.
A diverse audience uses our dashboards. We have software and data engineers tracking daily metrics, commercial and business teams pursuing client interaction and interest, and product managers, senior managers, CTO, CPO, CEO interested in overall user engagement and product growth, and adoption. Dimensional data modeling allows us to cater to all these needs effectively.
This article is a first in the series of blog entries about Dimensional Modeling. We plan to cover several topics briefly mentioned here, and others, in detail in the future. Be sure to follow Doximity Engineering @dox_engineering if you'd like to be notified about new blog posts.
Thanks to all the reviewers and Hannah Gambino for the illustration.
Be sure to follow @doximity_tech if you'd like to be notified about new blog posts.