
At Doximity, we have an internally-built gem called dox-messaging that all our applications use to interface with the Kafka backend. It has been a wrapper for ruby-kafka. Its purpose is to provide a more user-friendly API to interact with Kafka while also enforcing best practices and providing sane defaults for configurations that are more aligned with our unique use cases.
As our Kafka usage has grown, we’ve encountered problems such as bottlenecks in downstream services when consumers are processing messages, heartbeats being on the same thread as processing, and a lack of timely feature releases from ruby-kafka.
The heartbeat issue has been particularly frustrating. Heartbeats are only sent when the consumer polls Kafka for more messages. This can only occur when all previous messages have been processed. Upon a heartbeat timeout, all consumers in the consumer group must be rebalanced and partitions reassigned.
Often, these rebalances would get caught in a loop due to the slow message processing causing all processing to grind to a halt. I fondly refer to this predicament as a “rebalancing storm.”
Enter rdkafka-ruby (rdkafka), our saving grace. This is a simple wrapper gem around the C library librdkafka, which is without question the most up-to-date and widely used Kafka library in the Kafka ecosystem.
A short list of differences between the libraries here:
| rdkafka | ruby-kafka |
|---|---|
| Wrapper around the C librdkafka library. Uses Ruby-FFI to bind Ruby and C methods | Ruby client that implements the Kafka protocol from scratch. |
| Only limited by what librdkafka implements. | Kafka features must be reimplemented. |
| Faster than Ruby since it's C. | Slower since it's pure Ruby. |
| Heartbeats are sent through a background thread separate from processing. | Heartbeats and processing are in the same thread. |
These differences were strong enough to dedicate time towards a proof-of-concept (PoC) of rdkafka-ruby with our gem.
Where we started
Thanks to the thoughtfully-designed code architecture of our gem, I was able to rip out all of the ruby-kafka code within our dox-messaging gem and replace it with rdkafka.
Our gem has a factory pattern that is used for creating producers and consumers. This decouples “wanting to create an object” from “how to create an object.” Our apps primarily use factory interfaces to interact with the gem. All I had to do was keep these interfaces unchanged and consistent while rewriting everything underneath.
We also utilize an object for all Kafka client configurations which can be overridden by apps via our Rails initializers and class attributes.
With the above, I was able to develop a PoC for the updated gem in under two weeks. Using a test Rails app that I call kafka-rails-sandbox I ran a few benchmarks; when producing 10k messages, rdkafka was 1.5 seconds faster. This isn’t a huge difference, but it adds up over time:
rdkafka producer benchmark:

ruby-kafka producer benchmark:

Shown below: benchmarks of the consumers processing 10k messages, showing rdkafka is 5.3 seconds faster than ruby-kafka.
rdkafka consumer benchmark:
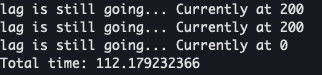
ruby-kafka consumer benchmark:
At Doximity, a successful PoC is followed by a written proposal. After much deliberation across all R&D, this project was given the green light.
Getting ready for production
Before removing legacy code, it was necessary to plan for some features from ruby-kafka that were not supported by rdkafka: a pause mechanism on partitions and instrumentation features such as collecting metrics with statsd and dynamic tracing.
To address the missing instrumentation features, it was necessary to develop them from scratch. We also had to redo error handling in the gem because of the namespace changes. For example, Kafka::ProcessingError and the like are now just Rdkafka::RdkafkaError with a code and message attached. This changes how we report exceptions to bugsnag and how we filter exceptions within a rescue.
There was also no way to set topic-specific configuration when creating a topic via rdkafka. We spin up environments dynamically in development, and topics are automatically created as Kafka is constructed. Additionally, there was no batched consumer in rdkafka so we had to decide whether to build our own or add it to rdkafka ourselves.
All the above items were not impossible to solve but certainly delayed our rollout.
Thankfully, the rdkafka project maintainers were incredibly helpful when we opened public pull requests. Their responsiveness built additional confidence in using their project.
At the time, rdkafka was picking up in popularity in the Ruby community and a few notable Ruby projects started to also see the limitations that we had noted. A pull request for a batched consumer/poller was added and merged which saved us some time. The development of the other missing features being placed into our gem went smoothly. We were cruising along and started to set our sights on getting this rolled out to production starting with low-risk applications.
Segmentation Faults
The biggest pain point of the project was encountering segmentation faults (segfaults) during the production rollout. These unfortunately were not seen in our testing due to differences between the sample testing of production traffic, and actual production traffic. However, our strategy of deploying to the least impactful apps first prevented impact to more critical workloads. Bugs were patched quickly but kept popping up.
The segfaults were occurring in two different situations. The first was with app bootup and initialization. The second dealt with runtime, which we’ll get to later. We do over 100 deployments a day, meaning our apps reboot over 100 times a day. Comparatively, pre-production has fewer processes running. We are also using different application servers in some environments such as Puma and Passenger in our Kubernetes and EC2 deployments, respectively.
Segfaults seen in initialization
We use a preloading concept in Passenger for Rails components and objects. This is especially important for external connections such as Redis, MySQL, and Postgres. Once the preloader finishes, it forks all objects to the Passenger worker processes. The big problem here is that rdkafka was not designed to be preloaded in this manner.
Rdkafka spins up a C thread that does most of the work under the hood. This is a space of memory that is not designed to be forked by two different processes. As such, when the worker process went to access the rdkafka memory space that was allocated by the preloader, we got a segfault because the memory space is illegally accessed.
Confusingly, we didn’t see this every time; it was a sporadic issue.
We suspected our Rails initialization logic was to blame, which is where the rdkafka instantiation resided. Subsequently, we had to figure out a way to push the initialization of rdkafka to post-preload. Utilizing an after fork spawn hook in Passenger solved this. Our code in the initializer for rdkafka ended up looking like this:
PhusionPassenger.on_event(:starting_worker_process, &configure_producers) if defined?(PhusionPassenger)
&configure_producers is a block call to pass in an array of producer classes to our gem’s producer factory. This would return a large global array called $producers (this global being a piece of tech debt we weren’t already happy about) of returned instantiated producer objects that are called upon within various areas of the Rails app.
Passenger isn't the only server we use in all environments, we noticed the same problems popping up elsewhere. Spring, which we use in development, does a similar forking to Passenger. To fix this we added Spring.after_fork(&configure_producers) into the Rails initializer. We also use Puma in other production environments which require more changes to this same initializer.
We realized we were in code smell territory and eager-loading our producers. We were doing this wrong.
Fixing segfaults in initialization
Our solution to the issues above was our producer registry, introducing the concept of lazy loading these rdkafka clients with our dox-messaging gem so the apps no longer have to eager load them. Basically, producers are now stored under the Dox::Messaging::Registry::Producers namespace. This removes the need for a $producers global. Even better, this also makes it so the rdkafka client isn’t created until it’s first used in the Rails app, long after it’s booted up and starting to take on traffic.
We use a factory pattern with our producers. A producer class has various attributes and methods that can be overridden, a manifest to the factory. The producer registry uses this factory to create producers that don’t exist yet; created producers are then cached locally. While the Rails app is calling #send_message the cache is being checked for the corresponding producer. If it doesn’t exist, the producer registry will create it using the factory, and then proceed with the initial #send_message call.
Going from something like this:
$producers[:my_producer].send_message(My::Message)
To:
Dox::Messaging::Registry::Producers[::My::Producer].send_message(My::Message)
Happily, the producer registry resolved all our initialization segfaults.
Fixing segfaults during runtime
As mentioned earlier, we also saw segfaults during runtime in Kubernetes (k8s) running through Puma. These were unique segfaults because Puma was not forking anything, so the previous initialization concerns weren’t in play. The segfaults would occur randomly regardless of traffic or load changes and would happen to multiple pods across different hosts.
Initial theories suspected resource issues. Perhaps the memory guarantees on the pods weren’t high enough and random spikes in memory usage caused us to overflow memory. Our metrics didn’t show such spikes but did show memory usage getting pretty close to the maximum allocated to the container. Due to how lean we ran this app on k8s this theory actually had some validity, so we increased memory limits. This had a positive impact and the segfaults were now less frequent but continuing to happen.
We moved to another theory. The app we were troubleshooting is a webhook for analytics data coming in from Segment. Segment sends analytics data to this webhook which then forwards the data to Kafka for more independent downstream processing. Maybe Segment was sending us corrupt data which caused the crash?
Digging into the callbacks on Segment, we saw many sporadic 502’s. The timestamps of the 502’s correlated with the crashing pods caused by the segfaults. However, Segment retries failed requests and eventually, all were successfully sent. Additionally, our data is Avro encoded as it’s going through the producer. If the data was in fact corrupt in some way we would have seen plenty of encoder exceptions which never happened, so this theory was bunk.
Around this time, the rdkafka-ruby project was finalizing its 0.11.1 upgrade. This version upgrades the underlying librdkafka library from versions 1.4 to 1.8; a pretty large jump with lots of fixes for bugs and crashes. Our last hope was to upgrade to this version and that the bug fixes would patch the runtime segfault. Otherwise, it would be necessary to dig deeper into the librdkafka C side–an unappealing prospect as I am not a seasoned C developer. But, I was prepared to do whatever I needed to fix this.
A release candidate gem was rolled out just for this app in k8s to see if the new rdkafka version would be of help and to our immense relief, it did. The runtime segfault was completely fixed!
We saw various fixes for crashes in the changelog between librdkafka versions 1.4 and 1.8. There could have been a single reason for the segfault issue or multiple different reasons. Based on our judgment the latter seems to be the most likely explanation. The important thing is that this is fixed and we can move forward.
Where we ended up
The segfaults were difficult to work through, particularly those seen during runtime. You can do as much pre-prod testing as you want, but you still might miss something, especially when rolling out a change of this size. (We’re talking thousands of lines of code.)
We were fortunate that the segfaults didn’t impact our workloads and were more of an annoyance for anyone on-call, so we were able to tackle this without a ton of “production is down!” pressure. This ordeal caused reasonable hesitation from some outside the project about moving forward. Calls were made to roll this back and even potentially scrap it altogether. But we persevered because we had confidence in our decisions and the resulting spoils from this outweighed any difficulties encountered.
What are the spoils of this? For starters, no more constant consumer group “rebalancing storms” impacting our processes by slowing things down and frustrating those who rely on this timely processing. I got my days back and am no longer barraged by Slack pings and PagerDuty alerts. I am able to focus on higher-level projects and work that makes a difference.
Also, we can now take advantage of new features that are coming out such as static membership, which will make our consumer groups more efficient and recoverable during an issue or deployment.
The processing speed of both our producers and consumers has increased dramatically. On the graph below, you can see the effect rdkafka had on the throughput speed of this particular consumer. Right after deployment, the line shoots straight up and to the right:
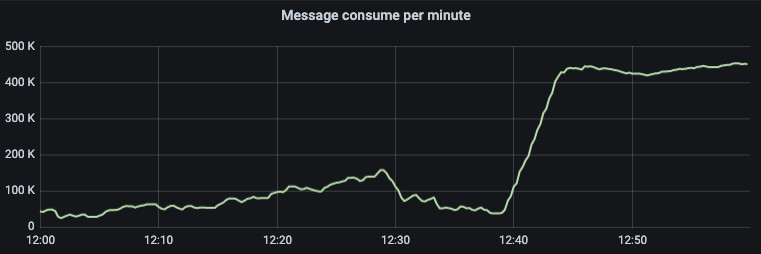
The previous peak performance of this consumer was 150k if we got lucky. The average performance was under 100k per minute. Now, the minimum performance is never under 400k. This means our consumer lags across the board have improved.
We would normally have a handful of consumer groups with a processing lag of 100k and above. Sometimes we would have consumer lags in the millions for a good chunk of the day, as the old ruby-kafka consumers were trying to catch up.
Here is an example of this:
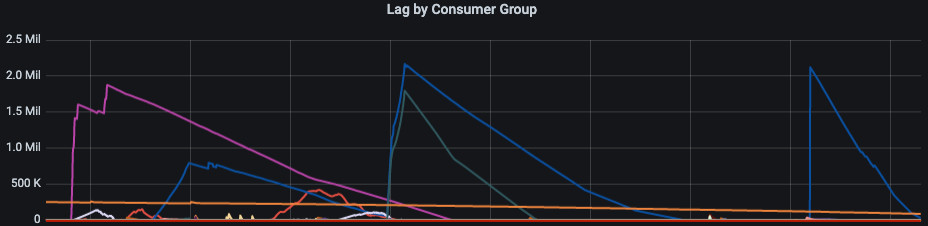
To increase throughput to counteract the lag, you would simply increase the number of consumers you have (up to the same amount of partitions), but that barely helped us and often made the problem worse. The more consumers we added to our groups increased the chances of a heartbeat timeout which would lead to more rebalancing.
Here’s a snapshot of what our lags look like on a typical day now:
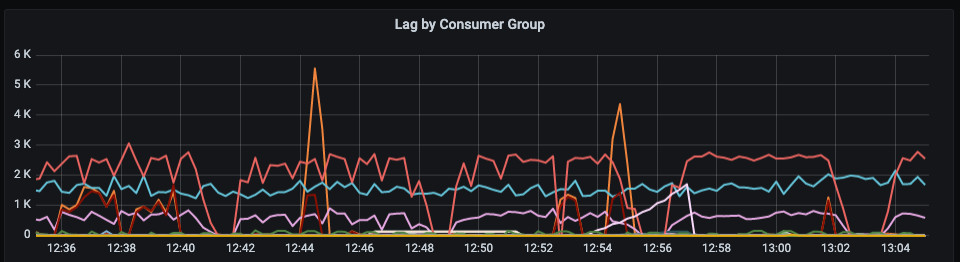
Much better.
Running Kafka processing on C and splitting out consumer heart beating in its own thread were not the only changes made. Another crucial change was adding distributed architectures to balance load more efficiently, which helped remove bottlenecks downstream of consumers. However, this alone wouldn’t have fixed our frustrations if we stuck with ruby-kafka.
Conclusion
Doximity’s setup had gotten more complex and required a library that could adapt to our unique use cases. For us, that library was rdkafka-ruby.
Like any large migration, this one had its surprises and pain points. However our ability to do frequent and small releases allowed us to learn and patch bugs quickly as they came up.
We built a more efficient gem that allowed us to remove tech debt, increase processing speeds, fix bugs, and enable new features. This required a degree of follow-through, deep diving, and learning beyond our wheelhouse to see it through.
Be sure to follow @doximity_tech if you'd like to be notified about new blog posts.