
Matching the Tool to the Task
A Quick Recap
In a previous article, we focused on the strengths of Large Language Models (LLMs), traditional Machine Learning (ML), and statistical methods and recommended 4 key questions to help you choose the right tool for a data solution.
- Your Data: Is it structured or unstructured? Bounded or unbounded?
- Your Goal: Do you need prediction, generation, or inference?
- Your Data Volume: Are you working with massive datasets or limited samples?
- Your Need for Transparency: Is deep explainability or strict repeatability a requirement?
The key takeaway was that LLMs excel at understanding and generating unstructured, unbounded language; ML models are the gold standard for prediction on structured data; and statistics are invaluable for inference and causality, especially with limited data.
However, the most complex and valuable real-world problems rarely fit neatly into one box. What if you need to understand unstructured customer feedback and use it to accurately predict churn? This is where hybrid approaches come in, combining the capabilities of each tool to create a system that is greater than the sum of its parts. Below, we present a few examples showcasing how working with hybrid data approaches helps unlock greater value.
Hybrid Data Solutions
In our experience, the most effective data solutions often emerge from combining multiple data modeling approaches. Rather than viewing LLMs, ML, and statistics as competitors, we recommend considering them as complementary parts of your broader data toolbox.

1. A Multi-Layered Fraud Detection System built using ML, LLM and Statistics
Let’s consider a high-stakes and regulated environment of a payments processing system. The primary challenge is to detect and block fraudulent transactions in real-time without incorrectly declining legitimate purchases. In addition, the decision-making process should be transparent and auditable.
The analytics workhorse of such a system will be a real-time transaction scorer, which can be an ensemble machine learning model. These models are fast and highly accurate for structured tabular data. The model can look at various real-time features such as transaction data, device and connection fingerprints, velocity checks and historical aggregates to produce a real-time risk score. The transactions with a very high score can be automatically blocked, and those in a “gray area” can be flagged for manual review.
In tandem, an LLM could analyze unstructured text data associated with the customer, such as website content, customer support chat logs, product descriptions, etc. This model can detect patterns in customer complaints that are indicative of fraud.
These two layers can then be topped with a statistical explainability and governance layer. Statistical tools such as Partial Dependence Plots can give a global view of the feature’s importance, whereas Individual Conditional Expectation plots can show the marginal effect of features on the predicted outcomes of each individual instance of the ML model. The explainability layer translates the model’s complex calculations into understandable risk indicators, leading to faster and more accurate human decision-making. Further, statistical methods like Disparate Impact Analysis can assess whether a model’s predictions have a disproportionately negative impact on certain groups. If a model is found to be biased, the statistical evidence can then be used to retrain it with debiasing techniques.
We use a similar application of this methodology at Doximity to optimize our medical news email digests. These are highly personalized emails sent out to our clinician members to assist them in staying apprised of articles relevant to their daily practice. While sending an email isn’t as mission-critical as fraud detection, flooding a busy doctor’s inbox with irrelevant emails is a one-way ticket to erode trust with our users. We leverage Bayesian-based split testing to validate our final recommendations, which ensures that what we ultimately send out has the statistics to back it up.
For another example, see how Stripe uses a statistical explainability layer on top of its Radar AI model to understand risk factors and details about particular payments.
2. Enhanced Product Discovery Engine using LLM, RAG and ML
While traditional e-commerce search handles specific queries like “carry-on luggage with wheels” with ease, it struggles to interpret broader, inspirational requests such as “essentials for a beach vacation” or “must-haves for a long flight.” These queries reflect an exploratory mindset. Here is one way to evolve the search from a simple retrieval tool to a product discovery engine, helping users find items they were not explicitly looking for.
At its core, an LLM can act as an "imagination layer." It interprets vague queries and generates relevant product groupings. For example, for a "long flight," it might suggest a neck pillow, noise-canceling headphones, and compression socks. To ensure these suggestions are practical, a Retrieval-Augmented Generation (RAG) component can connect the LLM to a knowledge base of historical purchase data.
Next, the engine can use the LLM as a pre-processing tool to translate its own unstructured text into a structured format suitable for machine learning. LLM categorizes items (e.g., "noise-canceling headphones" as "electronics" and "comfort") and extracts key attributes ("long-battery-life"), and also lists complementary products.
Finally, these high-quality, structured features can be fed into a traditional machine learning model, such as a gradient boosting machine. The ML components serve as the "reality layer" validating, ranking, and optimizing the LLM-generated suggestions based on features such as user engagement, conversion predictions, and business metrics.
This approach combines the language understanding of the LLM with the predictive precision of ML, ensuring the final list of products shown to the user is not only creative but also highly accurate and personalized. At Doximity, we have long used traditional ML and statistics-based approaches to rank medical news articles that we believe will be most relevant to our users. The introduction of LLMs enhances this through our content identification process. An article's text is unstructured data that traditional methods struggle with. Since LLMs can effectively interpret this text, we are able to better understand what content clinicians are interested in and then use that to identify additional articles to split-test. The combination of these methods results in a much more effective product than any one approach could achieve on its own.
For a technical deep dive, see how Instacart incorporated LLMs into the model-driven search stack to include inspirational and discovery-driven content for their users.
3. LLMs as a Synthetic Data Factory for ML
A common obstacle in developing ML models is the lack of high-quality training data—or any labeled data at all. LLMs can help address this by generating synthetic data, unlocking ML development to tackle business problems.
As with any ML project, we begin by defining the prediction task and identifying the independent and dependent variables. We then gather whatever data is available; even a small or unlabeled dataset provides a starting point. If a small labeled dataset exists, we can fine-tune an LLM on it so that the model can learn statistical distributions, correlations, and structures in the data. Techniques like Differential Privacy can be applied during fine-tuning to ensure individual data points are not memorized or exposed. If no labeled data is available, we can still begin with a task-appropriate foundational LLM. The LLM acts as a “data factory,” producing synthetic data that captures the statistical properties of the original dataset without including any real, identifiable information.
An early and crucial step is to define clear evaluation criteria with subject matter experts. LLM-based judges can be instructed to assess record quality according to this criteria, and rejection sampling or active learning can be used to programmatically iterate until enough quality data is produced. By starting with a small batch that experts can review, we are introducing critical feedback that improves LLM judgment and yields additional labeled data for additional fine-tuning of our data synthesization LLM. This refined model can then generate a larger, high-quality synthetic dataset.
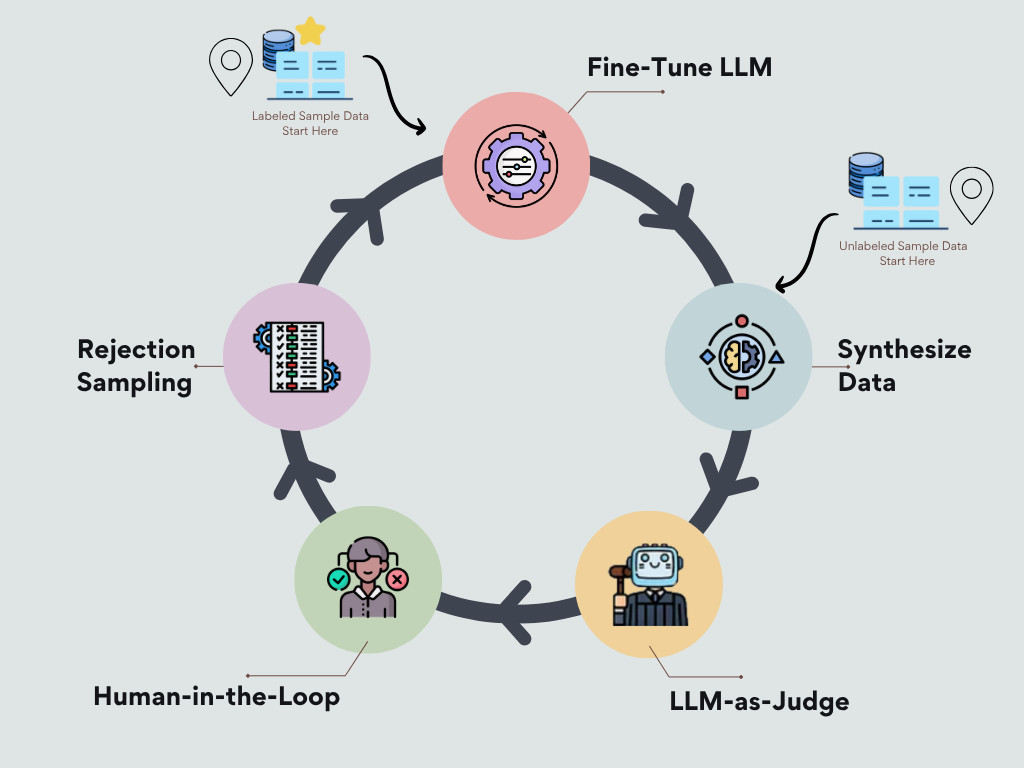
This privacy-preserving synthetic data can be used to train ML models like classifiers or regressors for specific business problems. Research shows such models can perform on par with those trained on real data. At Doximity, we’re already observing the benefits of this approach in a variety of our applications of fine-tuned LLMs.
A More Powerful Toolbox
The lines between LLMs, ML, and statistics are blurring; not because one is replacing the others, but because they are being combined in increasingly sophisticated ways. The future of applied AI is hybrid. By learning to use these tools in concert, data practitioners can move beyond the limits of any single method and build systems that are more accurate, trustworthy, and capable than ever before.